Ez a cikk egy, az elosztott rendszerek és a mikroszervíz-alapú alkalmazások komponensei közötti üzenetküldési lehetőségekkel foglalkozó cikksorozat harmadik része. Az első rész az SQS Standard Queue-ról, a második az SQS FIFO Queue-ról szólt, a sorozat további részeiben tervezzük az SNS és az Amazon MQ tárgyalását.
Az Amazon Kinesis nem egy konkrét szolgáltatás, hanem több szolgáltatás gyűjtőneve. A több szolgáltatás közül ebben a cikbben a Kinesis Data Streams-szel foglalkozunk, de az egyszerűség okán a cikkben sokszor csak Kinesisnek hívjuk majd.
A Kinesis Data Streams azon felül is sok szempontból hasonlít az SQS-re, hogy ezzel is az alkalmazásunk részei között küldhetünk üzeneteket:
- Több producer küldhet üzeneteket egyetlen helyre,
- több consumer veheti el az üzeneteket,
- maga a szolgáltatás skálázható,
- mindig több AZ-ben, redundánsan tárolja az adatokat, azaz ha a Kinesis OK-t küldött a producernek, akkor adat már nem vész el.
És - ahogy látni fogjuk - rengeteg dologban különbözik az SQS-től. Emeljünk ki pár szóhasználatbeli eltérést:
- Az SQS-ben sorokat (queue) adtunk meg, a Kinesisben stream-ről (áram, áramlat) beszélünk, ezzel is hangsúlyozva, hogy a Kinesisben arra számítunk, hogy az adatok, bár kis csomagonként, de gyakorlatilag megszakítás nélkül érkeznek.
- Az SQS esetében üzenetekről beszélünk, a Kinesis esetében rekordokról.

Hol használjuk a Kinesis-t?
Már említettük, hogy alapvetően olyan helyeken, ahol az adatok folyamatosan jönnek:
- méréseknél, szenzorok adatainak feldolgozásánál,
- online játékoknál,
- naplóüzenetek és metrikák begyűjtésekor.
A felhasználás körét lényegesen módosítja, kitágítja az SQS-hez képest, hogy a feldolgozott üzenetek megmaradnak a Kinesisben. Ez lehetővé teszi, hogy amíg az alkalmazásunk egyik része el van foglalva az adatok feldolgozásával, értelmezésével (például egy játék esetén a játékosok mozgatásával), addig egy másik rész, egy másik mikroszervíz például statisztikát készít ugyanabból a streamből.
Shardok
Amikor létrehozunk egy Kinesis Stream-et, egészen biztosan létrejön benne egy shard (szilánk, töredék), de egy streamben lehet több shard is. A rekordok mindig egy konkrét shardba kerülnek a stream-en belül. Ezek a shardok azok, amik az adatátbocsátás sebességét meghatározzák. Egy shard képes
- 1 MB adatot és
- 1000 PUT műveletet
feldolgozni másodpercenként. Amelyiket először elérjük, az korlátoz. Van olvasási korlát is: egy shardból másodpercenként 2 MB adat olvasható ki. Ha a három adat bármelyike korlátoz, akkor több shardra van szükségünk. Shardból régiónként egy AWS-fiók tízet kap, de ez soft limit, azaz az AWS Supportnál jegyet nyitva kérhető az emelése - százezerig.
Alaphelyzetben nem tudjuk közvetlenül meghatározni, hogy melyik shardba kerüljön az adatunk. Ha a "közvetlenül" kitételre felkaptuk a fejünk, jól tettük. A beérkező terhelés shardok közti egyenletes elosztását az AWS úgy igyekszik elérni, hogy minden rekordhoz meg kell adnunk egy partition key-t, ami alapján az AWS előállít egy int128(md5(partition_key)) pszeudokóddal leírható hash-t. Ez a hash dönti el, hogy melyik shardba kerül az adatunk. Az alaphelyzetben meglévő egyetlen shard minden lehetséges hasht-t fogad:
aws kinesis describe-stream --stream-name myStream
{
"StreamDescription": {
"Shards": [
{
"ShardId": "shardId-000000000000",
"HashKeyRange": {
"StartingHashKey": "0",
"EndingHashKey": "340282366920938463463374607431768211455"
},
...
Azt látjuk, hogy a streamünk nulladik - és egyetlen - shardja fogja átvenni az összes üzenetet, ugyanis a hash-intervalluma magába foglalja az összes lehetséges hash-értéket.
Ha kérjük, hogy legyen mégis két shardunk, akkor a fogadott üzenetek a hash-ek alapján két shardba kerülnek. Látjuk, hogy az eredeti shard nem tűnik el azonnal (a 0-s a régi, az 1-es és a 2-es shard az új):
aws kinesis update-shard-count --stream-name myStream --target-shard-count 2 --scaling-type UNIFORM_SCALING
aws kinesis describe-stream --stream-name myStream
{
"StreamDescription": {
"Shards": [
{
"ShardId": "shardId-000000000000",
"HashKeyRange": {
"StartingHashKey": "0",
"EndingHashKey": "340282366920938463463374607431768211455"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49610814757437399477767104689162985062854364633730383874",
"EndingSequenceNumber": "49610814757448549850366370000732543996171501345576058882"
}
},
{
"ShardId": "shardId-000000000001",
"ParentShardId": "shardId-000000000000",
"HashKeyRange": {
"StartingHashKey": "0",
"EndingHashKey": "170141183460469231731687303715884105727"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49610816975759426611203780447145488798005255947107172370"
}
},
{
"ShardId": "shardId-000000000002",
"ParentShardId": "shardId-000000000000",
"HashKeyRange": {
"StartingHashKey": "170141183460469231731687303715884105728",
"EndingHashKey": "340282366920938463463374607431768211455"
},
...
A két új shard kapja az új rekordokat. Ha mostantól kellőképp különböző partition key-eket adunk meg a rekordok elküldésekor (például a játékunkban az adott játékos felhasználóazonosítóját), akkor megvalósul a shardok egyenletes terhelése. Az azonos primary key-jel rendelkező üzenetek egészen biztosan ugyanabba a shardba kerülnek.
Bizonyára vannak olyan olvasóink, akiknek nem csak a "közvetlenül", hanem az "alaphelyzetben" szó is szemet szúrt. Nos, van lehetőség arra is, hogy az emlegetett hash-algoritmust felülbírálva, közvetlenül megadjuk a hash-t a beküldött rekord mellé. Ez az érték persze így nem lesz hash (nem hash-eltünk semmit), de azért úgy hívjuk. Ilyen módszerrel az alkalmazásuknak módjában áll eldönteni, hogy melyik shardra kerüljön a rekord.
Rekordok beküldése
Rekordokat (amik ugyebár legfeljebb egy megabájtosak lehetnek) base64 eljárással kódoltan adhatunk meg:
aws kinesis put-record --stream-name myStream --partition-key 'walami' --data 'TmFow6F0LCBlbG9sdmFzdGFkPwo='
{
"ShardId": "shardId-000000000001",
"SequenceNumber": "49600902273357540915989931256901506243878407835297513618",
...
A base64 kód előállítása Unix-szerű rendszereken egyszerűen az echo 'Üzenet'|base64 paranccsal történhet. Ha ez a lehetőség nem áll rendelkezésre, vagy úgy kényelmesebb, hamar találunk az interneten base64-átalakítást végző weboldalt.
Rekordok kiolvasása
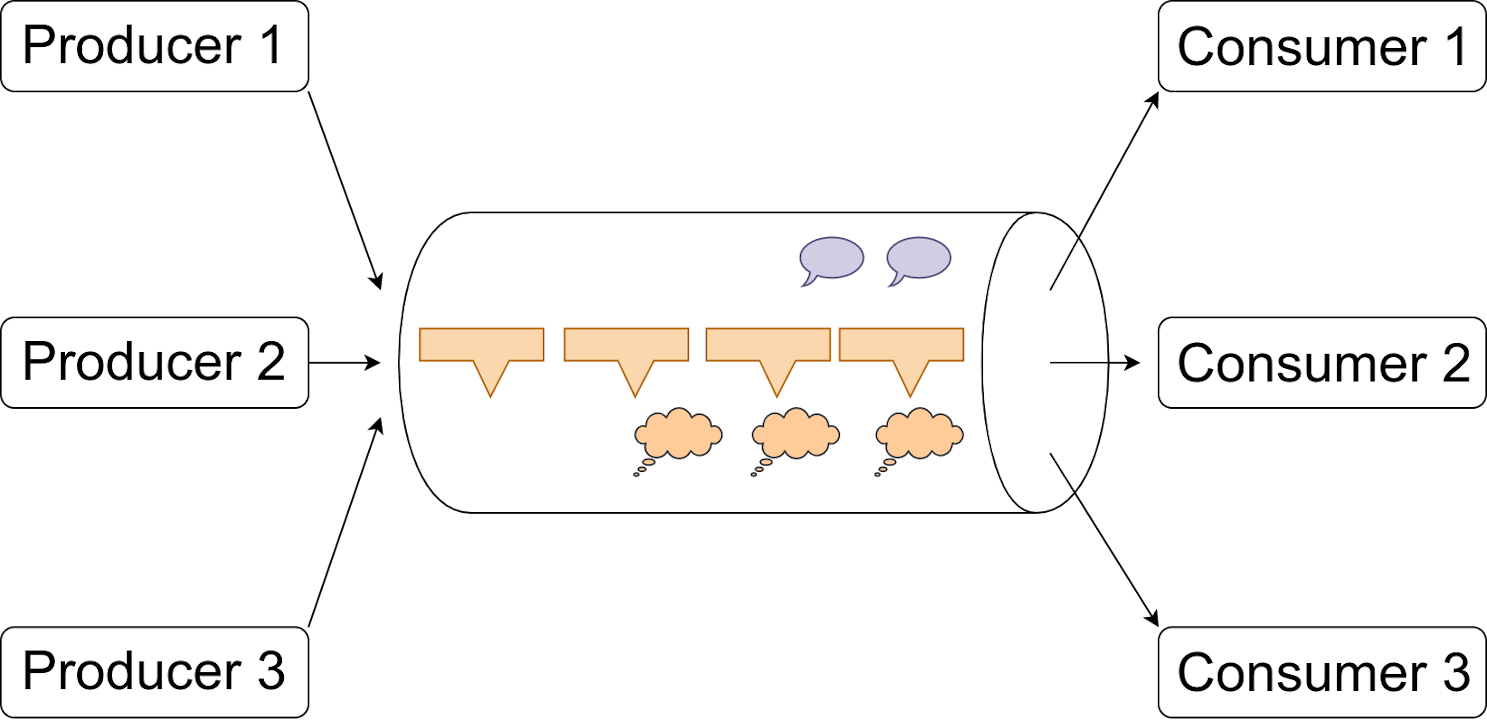
Hűséges olvasóink hajlamosak lehetnek úgy vélekedni, hogy a mellékelt kép ugyanaz, mint amit az SQS FIFO-soroknál bemutattunk. Igazuk is van, eltekintve egy apró, ám jelentős különbségtől: a jobb oldali nyilak ezúttal a "cső" fölött kezdődnek, ezzel szemléltetve azt, hogy az olvasás nem a streamből, hanem egy adott shardból történik. Emlékszünk még az SQS-re? Ott azt mondtuk - amit az AWS is -, hogy a "next best" üzenetet adja oda a sor, nem tudjuk eldönteni, hogy melyik üzenetcsoportból olvasunk. Hát itt nem csak hogy tudjuk, egyenesen kell. Na és melyik shardra került a beküldött rekord? Ugyan kiírta az aws cli, amikor az előző parancsot kiadtuk, de a stream másik végén hallgatózó alkalmazásunk erről mit sem tud. Ha épp tervezési fázisban vagyunk, segítségünkre lehet az alábbi Python egysoros:
python3 -c "import hashlib;print(int(hashlib.md5('walami'.encode('utf-8')).hexdigest(), 16))"ITERATOR=$(aws kinesis get-shard-iterator --stream-name myStream --shard-id shardId-000000000001 --shard-iterator-type TRIM_HORIZON --query 'ShardIterator')aws kinesis get-records --shard-iterator $ITERATOR
{
"Records": [
{
"SequenceNumber": "49610816975759426611203780447152742352923072502454812690",
"ApproximateArrivalTimestamp": "2020-09-15T14:08:07.358000+02:00",
"Data": "TmFow6F0LCBlbG9sdmFzdGFkPwo=",
"PartitionKey": "walami"
}
TRIM_HORIZON pedig az első kiolvasatalan értéktől indít. Az iterátor adott ideig érvényes, és mindig megkapjuk a következő iterátort is, mert jól elképzelhető, hogy mire az elsővel kiolvassuk az adatokat, újak kerülnek a shardra.
Rekord törlése
Ez a szakasz rövid lesz: nincs mód rekordot törölni a Kinesisből. A rekordok a retenciós idő lejártával automatikusan ürülnek. Ez az idő alapesetben 24 óra, és legfeljebb 168 órára növelhető.És miért ne használjunk SQS helyett mindig Kinesis-t?
Szinte annyi shard-ot hozunk létre, amennyi tetszik, az üzenetek biztosan sorban érkeznek meg, és amennyiben a producerünk megkapja az OK-t, még duplák sem kerülnek a streambe. Mi szól mégis az SQS mellett? Alapvetően a Kinesis-re támaszkodó alkalmazás komplexitása. A mi dolgunk figyelni arra,
- hogy minden shardot "igazságosan" olvassunk,
- hogy ha új shardot hozunk létre a bemenő oldalon, akkor a kimenő is értesüljön róla,
- hogy melyik rekordot olvastuk már (bár ebben a Kinesis segít), ami különösen akkor válhat bonyolulttá, ha több consumerünk is van.
Az AWS is látja ezt a problémát, és rendelkezésre bocsátja a Kinesis Consumer Library-t a fejlesztők életét megkönnyítendő. Párjával, a KPL-lel (P mint Producer) együtt hasznos segédeszköz lehet sok esetben.
Befejezve mélyreható áttekintésünket, búcsút veszünk a Kinesis Data Streams-től. Remélhetőleg tudtunk segíteni azoknak a rendszertervezőknek, architecteknek, akik épp e technológia felé pillantgatnak.