Kubernetes az AWS felhőjében: EKS
Lassan mindenki megszokja, hogy a csapból is konténerizáció folyik. Nem véletlen: a konténereket számos előnyük teszi igen vonzóvá mind a fejlesztésben, mind az üzemeltetésben dolgozók számára. A konténerizáció ipari méretekben elképzelhetetlen a konténerek működését összefogó réteg, a konténer-orkesztrátor nélkül, aminek de facto ipari szabványa, a legtöbbet használt környezet a Kubernetes. Pillanatok alatt induló izolált számítási környezetben futó konténerek, továbbá
- a terhelés változásának függvényében skálázódó hagyományos, monolitikus alkalmazások,
- és komponensenként skálázódó mikroszervízes környezetek,
- fokozatos és visszagörgethető migráció,
- azonnal induló fejlesztői image-ek,
- egyszerű profiling,
- hatékonyabb erőforrás-kihasználás,
- nyílt, követhető fejlesztési folyamatú forráskód
 – talán ezek azok a kifejezések, amelyeket egyetlen valamirevaló, a Kubernetessel foglalkozó összefoglaló sem mulaszt el megemlíteni.
– talán ezek azok a kifejezések, amelyeket egyetlen valamirevaló, a Kubernetessel foglalkozó összefoglaló sem mulaszt el megemlíteni.
Csak a bátrabb ismertetők hangsúlyozzák a Kubernetes-clusterek üzemeltetéséhez megkívánt szakértelem mértékét. A Kubernetes‑üzemeltetés sok részterület ismeretét megkívánó külön szakma – ami nem könnyíti meg a bevezetését.
Kubernetes jelentős mértékű térhódításával párhuzamosan egy másik folyamat is alapjaiban alakítja át a szakmánkat. Felhőtechnológiákkal foglalkozó cégként nap mint nap közelről figyeljük, hogy hihetetlen tempóban vándorolnak be a mindenféle területen dolgozó és mindenféle méretű informatikai cégek a publikus felhőbe. E vándorlás eredményeként a nagy felhőszolgáltatók nem győzik építeni az újabb és újabb adatközpontokat. A publikus felhőbe való költözés kis hazánkban is – némileg megkésve és erősen megfontolt lépésekkel – a mindennapok részévé vált.
Az AWS, mint a publikus felhők általában – ideális helyszínt jelent a Kubernetes-clusterek futtatására, aminek két fő oka van. Az egyik a felhő lényege: az azonnal hozzáférhető, szabadon skálázható erőforrások rendelkezésre állása. A másik pedig az a tény, hogy az AWS óránként húsz centért átveszi tőled a Kubernetes-clustered lelkének, a Control Plane-nek a kezelését.
De mi is az a Control Plane? Egy Kubernetes-cluster, ha elég messziről nézzük, kétféle számítógépből vagy virtuális gépből áll. Az egyik gép vagy egyik gépcsoport a Control Plane feladatait látja el, azaz többek között
- API-t tesz elérhetővé a cluster gépei és felhasználói számára
- tárolja a cluster adatait
- dönt arról, hogy a konténereket tartalmazó podok melyik számítógépen fussanak
- figyeli, hogy rendben futnak-e a podok, és ha nem újakat indít helyettük
- összekapcsolja a clustert a felhőszolgáltató API-jával
A másik gép, vagy gépcsoport – a worker node-ok – pedig a lényegi munkát végzik: itt futnak az alkalmazásunk konténereit tartalmazó podok.
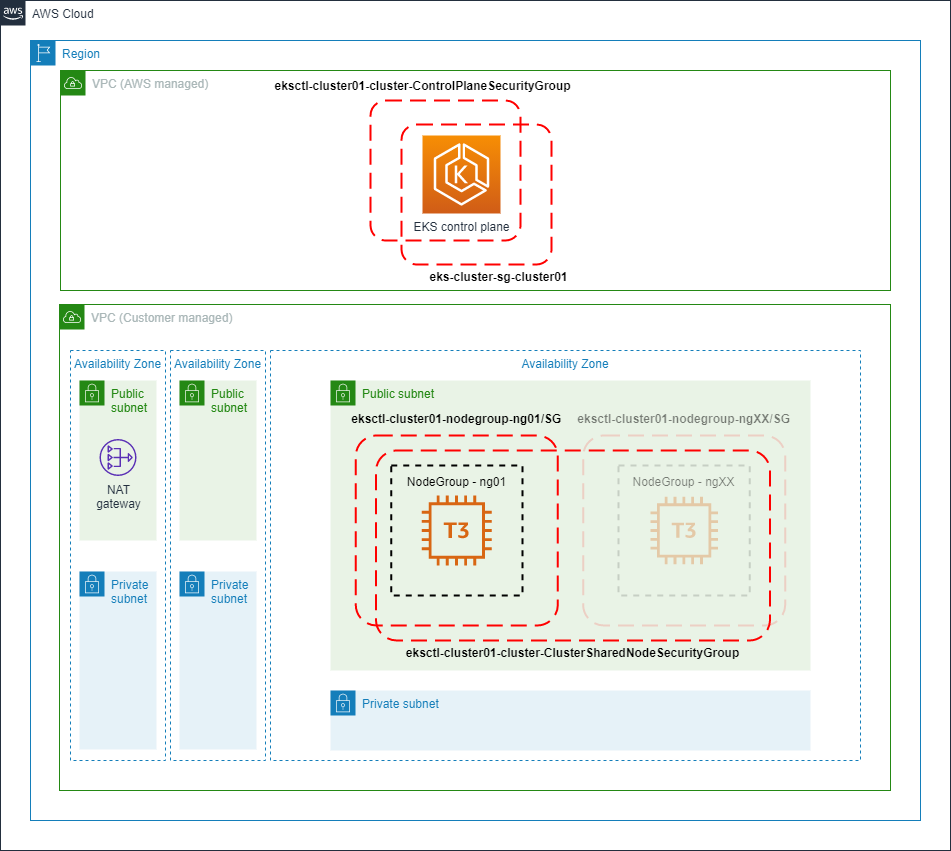
Elastic Kubernetes Service
Az AWS EKS szolgáltatása nagyon meggyorsítja a Control Plane kialakítását. A Control Plane üzembeállítása a felhőben méréseink szerint átlagosan tíz percet vesz igénybe. Ráadásul az eredmény egy magas rendelkezésre állású (HA) Control Plane, ami olyan esetekben, amikor a worker node-ok és a rajtuk futó podok száma megköveteli, automatikusan skálázódni fog. A Control Plane üzemeltetésén kívül automatikusan kialakul a konténerek egymás közti hálózati kapcsolatát megvalósító réteg is. Az előbb említett húsz centért nem csak a Control Plane, hanem a hálózati réteg üzemeltetését is megkapjuk.
Így már „csak” a worker node-okkal kell törődnie az üzemeltetői csoportnak. A worker node-ok az AWS virtuális gépeiből, azaz EC2-példányokból alakíthatók ki. Dönthetünk úgy, hogy teljes felügyeletet szeretnénk felettük. Ilyenkor a mi dolgunk a node-ok indítása, az operációs rendszer felkészítése, a Kubernetes-eszközök telepítése és a node clusterbe léptetése. Bár a feladat ellátást nagyon megkönnyíti az eksctl nevű parancssori eszköz, marad még elegendő feladatunk – különösen a worker node-ok operációs rendszerének frissítésével. Ha a virtuális gépek fölötti teljes felügyelettel járó feladatok egy részéről örömmel mondanánk le, akkor lehetőségünk nyílik menedzselt node-ok használatára, velük például az operációs rendszerek frissítése is egyszerűbb.
Földi körülményekben gondolkodók számára egészen újszerű megközelítést jelent az a megoldás, amikor a munkaterhet – a podokat és a bennük futó konténereket – nem virtuális gépeken, hanem a Fargate-ben helyezzük el. A Fargate úgy teszi lehetővé konténerek futtatását az AWS-ben, hogy nincsenek többé worker node-jaink. Nem virtuális gépeket, hanem csak processzorokat és memóriát vásárolunk. Ha tudjuk, hogy az alkalmazásunk futtatásához huszonegy processzorra és tizennyolc gigabájnyi memóriára van szüksége, akkor kérünk ennyit – és nem érdekel bennünket, hogy ez hány számítógépet jelent a valóságban, vagy azokon milyen operációs rendszer fut. Nem marad kihasználatlan erőforrásunk sem.
Ennyi?
Az EKS szolgáltatást nagy vonalakban összefoglaltuk, de igazán akkor érdemes a Kubernetes-clusterünket AWS-felhőben futtatni, ha megtanuljuk kihasználni az AWS egyéb eszközei nyújtotta lehetőségeket. Hadd emeljünk ki néhányat.
A fájlalapú adatainkat tároló storage alighanem EFS-re fog kerülni. Az Elastic File System kialakítása olyan fájlrendszert ad a kezünkbe, amely „nyúlik”: nem kell megmondanunk előre, hogy mekkora legyen, és a tárolt adat alapján számláz nekünk az AWS. Ezer konténer akar egyszerre hozzáférni? Vagy tízezer? Nem gond. Lassulni fog? Ha úgy állítjuk be, és úgy fizetünk érte, akkor még azt sem. Az adatok redundáns tárolása magától értetődő, a beavatkozásunk nélkül megtörténik. A relációs adatbázisban tárolt adatainkat elhelyezhetjük menedzselt adatbázisokban. Az RDS szolgáltatás MySQL (vagy MariaDB), PostgreSQL, Microsoft SQL és Oracle szervereket futtat nekünk, automatikusan és percre pontosan visszaállíthatóan menti a tranzakciókat, szinkronban futó, és baj esetén az előtérbe lépő pót-szervert kérhetünk hozzá, vagy csak olvasható segédszerverek csatasorba állításával csökkenthető a fő szerver terhelése. Ha az adatainkat noSQL‑adatbázisban tárolnánk, választhatunk menedzselt MongoDB, és az AWS saját megoldása, a DynamoDB között.
A terhelés változására való dinamikus skálázódás két szinten valósul meg. A konténerek számát a meglévő worker node-jainkon a földi adatközpontokban is használt eszközökkel változtatjuk. változtatja, ha pedig elfogytak a worker node-jaink, akkor a Cluster Autoscaler indít nekünk új virtuális gépeket.
A podok között a beérkező terhelést az AWS terheléselosztói valósítják meg. Az Application Load Balancer az alkalmazásrétegben futva képes a HTTP-kérések vizsgálatával más-más mikroszervízt futtató podnál végződtetni a forgalmat, a Network Load Balancer pedig akkor van hasznunkra, ha nem HTTP protokollon érkezik a forgalom.
A worker node-jaink hálózati védelmét a tűzfalak mellett fokozhatjuk azzal, hogy csak a terheléselosztót tesszük elérhetővé a nagyvilágnak, magukat a node-ok még publikus IP-címet sem kapnak.
Szinte biztosan érdemes összehangolnunk a Kubernetes és az AWS felhasználókezelését. A legtöbb esetben alkalmazhatunk bejáratot utakat, de a két rendszer alapos átlátását és a lehetőségek szemfüles kihasználását igényli a Kubernetes felhasználói csoportok AWS felhasználói csoportoknak való megfeleltetése.
Hamar népszerűvé vált kétnapos EKS-képzésünkön a fent említett technológiákkal egytől-egyig megismertetünk, képessé téve téged arra, hogy megkezdd saját Kubernetes-clustered kialakítását a felhőben.