Ez a cikk a DynamoDB-ben történő adatmodellezésről szóló cikksorozat második része (az első a kulcsválasztásról szólt) - és még ez után is lesz folytatás.
Az első részben abban maradtunk, hogy érdemes odafigyelni az elsődleges kulcs megválasztására. A kulcs nagyban meghatározza, hogy mennyire könnyen férünk hozzá az adatainkhoz, ugyanis kevés költséggel csak az elsődleges kulcsra tudunk szűrni (itt nincs olyan flexibilis eszközünk, mint az SQL-megvalósítások WHERE záradéka).
Talán még emlékszünk a múltkori, webshopos rendeléseket tartalmazó DynamoDB-táblára. Egy picit vltoztattunk rajta, mert a rendelések állapotát (nyitott vagy lezárt) jellemző status szó egy foglalt szó a DynamoDB-ben. Ha ezt szeretnénk attribútumként használni, akkor tornázni kell, és nem volna elég szép és letisztult a mintakód. Úghogy átkereszteljük stat-ra.
{
"client": "jozsi",
"ordertime": 20200706080245,
"stat": "open"
}
{
"client": "jozsi",
"ordertime": 20200706080244,
"stat": "closed"
}
{
"client": "johanna",
"ordertime": 20200706080245,
"stat": "closed"
}Ebben ugye összetett elsődleges kulcsunk van, azaz két "mező" együtt azonosít egy bejegyzést. A client a Partition Key, az ordertime a Sort Key, és remekül tudunk olyat kérdezni a DynamoDB-től, hogy
- add meg jozsi rendeléseit, vagy
- add meg jozsi 2020. júliusi rendeléseit.
A baj akkor jön, amikor azt kérjük, hogy "add meg a lezárt rendeléseket!" Na, ilyet nem tud a DynamoDB, hiszen a status nem része az elsődleges kulcsnak. Mi hát a teendő?
Az első gondolat
A DynamoDB táblái scannelhetők - a scannelés ez esetben szakszó, nem szleng, és azt jelenti, hogy egyesével visszakérjük az összes itemet (rekordot, ha úgy tetszik). Ezzel számos baj van:
- utólag nekünk kell kiválogatni a szükséges rekordokat;
- egyszerre legfeljebb egyetlen megabájt adatot kapunk vissza - ha ennél több van, akkor a DynamoDB "lapokra bontja" (paginate) az adatokat - nekünk kell figyelni, hogy van-e még oldal, és mindet egyesével elkérni;
- lassú lehet a válasz; és
- még drága is az egész: sok művelet, sok lekért adat.
A lekérdezés - sőt, nem is lekérdezés, hanem letapogatás - szintaxisa AWS CLI-ban a következő:
aws dynamodb scan --table-name OrderA sebességen dobhat, ha párhuzamos scannelést indítunk. A "sima" scan ugyanis akkor is csak egy fizikai partícióról olvas, ha a rengeteg adatunk sok partíción kap helyet. A scan sebességét tehát korlátozza a fizikai partíció sebessége. Párhuzamos scanneléskor a táblát szegmensekre osztjuk, és a programunk egy-egy szála, vagy az operációs rendszer egy-egy folyamata scannel egy szegmenst. A módszer működik, nem számít "ugly hack"-nek, de azért a kisujjunk sajgásából arra következtetünk, hogy az alkalmazásunk komplexitását éppen nem csökkenti.
FilterExpression
A FilterExpression arra való, hogy megszűrjük az adatokat, miután a scan végbement, de még mielőtt az adatokat visszakapnánk. A felsorolt bajok közül tehát csak az elsőt szünteti meg - s bár kétségtelenül nagy hasznunkra van, azért ez még távol áll a jótól.
A "lekérdezés" a következőképp alakul:
aws dynamodb scan --table-name Order --filter-expression "stat = :allapot" --expression-attribute-values '{":allapot":{"S":"closed"}}'Global Secondary Index
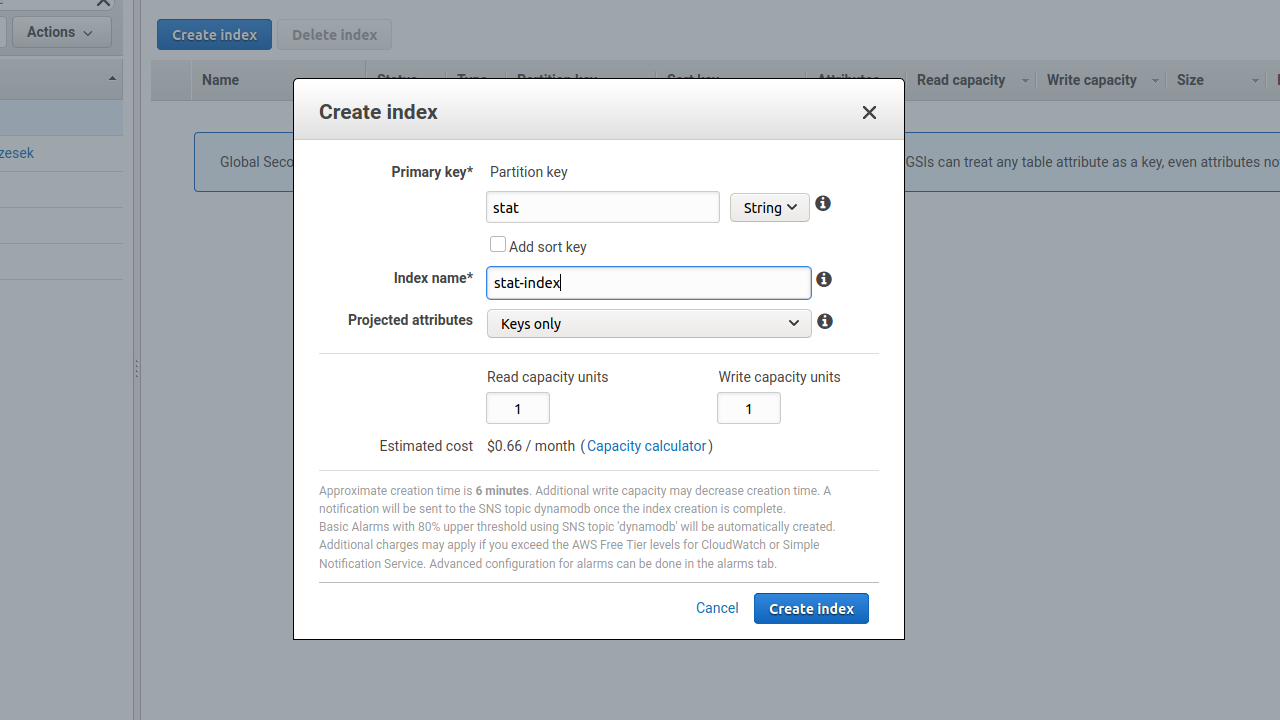
A GSI-k arra valók, hogy lekérdezhetővé tegyük a táblánkat az elsődleges kulcsnak részét nem képező attribútumokra is. Persze attól, hogy egy táblához létrehozunk egy GSI-t, a DynamoDB nem ruházódik fel szuperképességekkel, nem változik semmi. Akkor meg miért képes lefutni az alábbi lekérdezés?
aws dynamodb query --table-name Order --index-name stat-index --key-condition-expression "stat = :allapot" --expression-attribute-values '{":allapot":{"S":"closed"}}'(Megjegyezzük, hogy ez már tényleg lekérdezés, figyeljük meg, hogy a scan helyett query szerepel a parancsban.)
Szóval az történik, hogy a háttérben lényegében létrejön egy másik tábla, aminek az elsődleges kulcsát az eredeti tábla olyan attribútumaiból választjuk, amelyek eredetileg nem voltak kulcsok. Ez a tábla, akarom mondani, index
- saját nevet kap;
- az eredeti táblának nem feltétlen tartalmazza az összes mezőjét-attribútumát (spórolva a tárterületen), a képen például látjuk, hogy csak a kulcsokat másoljuk át a
statjellemzőn kívül (ja igen, nekünk astatmezőn kívül csak kulcsjellemzőink vannak a táblában, de a példát érted); - az eredeti táblával szinkronban tartja az adatait (az eredetin történik minden változtatás);
- a számára megadott írási-olvasási teljesítmény kiszolgálására képes (az eredeti táblától teljesen függetlenül);
- és külön fizetünk érte a tárterület és teljesítmény alapján.
Az első részben megfogalmazott tanulságaink így bővülnek:
- Nagyon gondoljuk át, hogy az elsődleges kulcson kívül még milyen attribútumoknak kell szerepelniük a lekérdezésekben
- és azt is, hogy a kulcson kívül milyen attribútumokat akarunk még visszakapni.
Ha kezdjük erősen sejteni, hogy amit SQL-ből tanultunk, az mehet a lecsóba, akkor igazunk van. Egy RDBMS használatakor a tábláink tervezésekor elvileg nem szempont az alkalmazás, ahol használni kívánjuk az adatokat. Elvileg, mert azért a denormalizáció meg a nézettáblák ott is vannak. Nos, a DynamoDB használatakor előbb kell tudnunk, hogy mit csinál az alkalmazás, és utána állhatunk neki táblát tervezni.
Legközelebb a GSI párjáról, az LSI-ről lesz szó.