Az AWS idén eddig két régiót nyitott összesen hat adatközponttal. A 2022-23-ra tervezett spanyol régiójuk már a hetedik lesz Európában, azaz ugyanannyi lesz belőlük, mint Észak-Amerikában. Az Azure tizennégy üzemelő és három bejelentett európiai régiójával hasonló jelenlétet képvisel. Aligha túlzás levonni azt a következtetést, hogy a felhő szerepe töretlenül növekszik.
A növekedésnek csak egy részét okozza a felhőben induló zöldmezős projektek nagy száma. A másik rész a felhőbe történő migráció, ami az esetek nagy részében együtt jár adatok mozgatásával is. Amikor sok adatot kell bejuttatni a felhőbe, akkor kerül a képbe az AWS DataSync. Erről a szolgáltatásról olvashatsz bővebben ebben a cikkünkben.
Milyen esetekben érdemes használnunk a DataSync-et?
- Amikor aktív alkalmazások migrálása során viszünk adatokat a felhőbe, lényegében egyszeri alkalommal,
- amikor újra meg újra adatokat juttatunk a felhőbe, hogy az ott lévő alkalmazásaink feldolgozhassák: például a felhőben renderelünk, vagy Big Data elemzést folytatunk,
- archiválunk, akár mert helyet akarunk felszabadítani az on-prem környezetünkben, akár mert az on-prem storage felújítása már nem a legkedvezőbb opció,
- az on-prem adatokat katasztrófa-elhárítási céllal másoljuk a felhőbe időről időre.
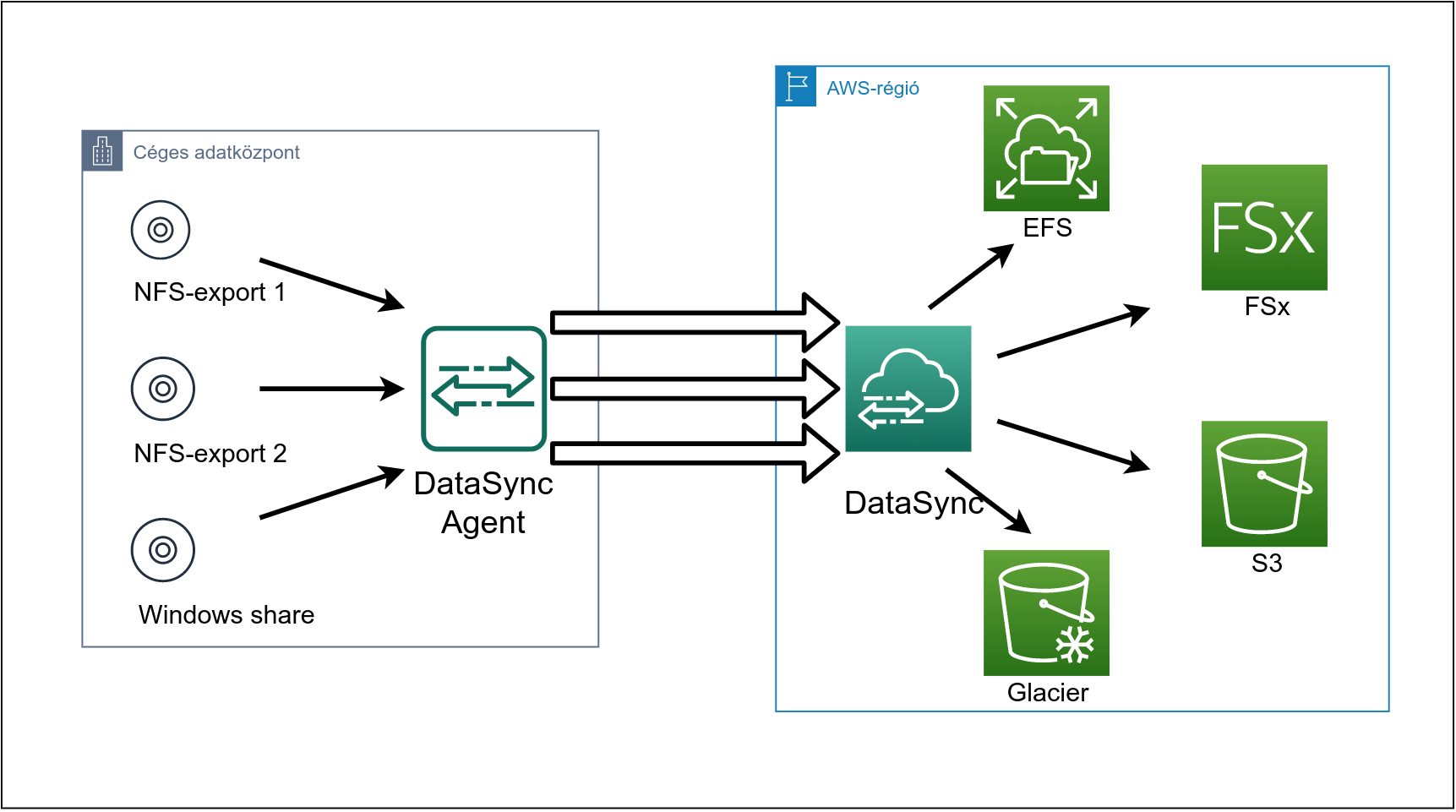
Amikor saját módszerrel végezzük az adattovábbítást, felmerül hogy:
- Milyen protokollt használjunk?
- Hogyan tömörítsük az utazó adatokat, és
- hogyan legyenek titkosítva?
- Kellenek-e a fájlrendszeri metaadatok, ha igen, miként tároljuk őket?
- És talán az egyik legfontosabb: az átvitt adatok validációja miként valósul meg?
Az eljárás kifejlesztése, tesztelése és karbantartása pénzt és időt emészt fel. Az AWS DataSync mindezek megoldására hivatott, teljesen menedzselt szolgáltatás. A tömörített adatokat több darabban, párhuzamosan szállítja, hogy minél rövidebb idő alatt a rendeltetési helyükre érjenek, akkor is, ha milliárdnyi kis fájlról van szó. Az AWS szerint akár tízszer gyorsabb másolást tesz lehetővé, mint ha például az AWS CLI-t használjuk. Hogyan működik a DataSync?
- A VMWare környezetünkben elhelyezünk egy AWS DataSync Agentet - ez lényegében nem más, mint egy virtuális gép.
- NFS vagy SMB használatával elérhetővé tesszük számára a szóban forgó adatot,
- amit az Agent erre optimalizált protokollon, párhuzamos átvitelen elindít az AWS felhőjébe, akár a publikus interneten, akár VPN-en.
- Az adatok célja lehet S3, lehet EFS (a jó öreg NFS Amazon-féle implementációja) vagy az FSx, ami szintén egy menedzselt blokkeszköz, de SMB-vel érhető el.
A DataSync Agent nem csak VMWare virtuális gép formájában, hanem két egyéb módon is elérhető. Az egyik az EC2, ahol nyilván akkor van értelme futtatnunk, ha egy másik AWS-régióba mozgatunk nagy mennyiségű adatot. A másik lehetőség pedig az a Snowcone, aminek a nagyobb tesójáról már mi is írtunk. Ez a lehetőség alig pár napja érhető el.
A DataSnyc vezérlése teljes egészében az AWS webes felületéből, az AWS-konzolról történik. Itt aktiváljuk a telepített Agentet: meg kell adnunk a publikusan elérhető IP-címét, és a 80-as, illetve a 443-as portját elérhetővé kell tennünk.
A következő lépés szinkronizálási feladat vagy feladatok definiálása az Agent számára. Egy feladat lényegében a következőképp hangzik:
- Csatlakozz ehhez-és-ehhez a megosztáshoz (NFS vagy SMB használatával),
- a metaadatok (időbélyegek, tulajdonos, ...) közül másold át, amiket megadok,
- töröld vagy tartsd meg, amiket a forrásból törlök,
- írd felül, vagy sem, amiket a forrásban felülírok,
- használhatod az egész sávszélességemet, vagy csak amennyit engedek,
- sorba állítható a feladat (ha egy Agentre több feladatot is bíznánk)
- miket szűrj ki (ha például csak a *.jpg menjen, a *.tiff ne),
- a CloudWatch melyik naplócsoportjába naplózz,
- a megérkező fájlok pedig
- ebbe-és-ebbe az S3-bucketbe (és azon belül melyik tárolási osztályba - Standard, Infrequent Access, Glacier, Glacier Deep Archive) vagy
- erre-és-erre az EFS-re vagy
- erre-és-erre az FSx-re kerüljenek.
Egy feladat akárhányszor újraindítható, és a DataSync elég okos ahhoz, hogy csak a változásokat másolja - lényegében inkrementális mentést végez. Az irány pedig nem adott: használhatjuk az adatok letöltésére is.
Ha sok a másolandó adat, akkor a feladat definíciója úgy is megadható, hogy egyszerre több Agent is megkapja a feladatot - ennek akkor lehet értelme, ha nem a sávszélesség a korlátozó tényező. Egy Agenthez másodpercenkénti 10 gigabites sávszélességet számolhatunk, persze, csak ha az infrastruktúránk is elbírja minden ponton...
A DataSync hozzáférése az EFS-ekhez, S3-bucketekhez az AWS-nél bevett módon, IAM Role-okkal szabályozható, ha pedig ismétlődő feladatvégrehajtásra van igény, akkor megoldást jelenthet akár a Lambda, akár egy helyi időzített feladat és a DataSync API.
De az AWS Storage Gateway ugyanezt tudja! - mondhatnánk. Nem volna teljesen igazunk. A Storage Gateway is tud sok fájlt AWS-be mozgatni, de ott ugye az a cél, hogy az "élő" fájlokat érjük el, a DataSync pedig másolatkészítésről szól. Ott folyamatos a szinkron, itt egyes időpontokban valósul meg. Más felhasználásra való.
De másolhatok az AWS CLI használatával is! - mondhatnánk. És igazunk volna. De a másolás lassabb lesz, nekünk kell figyelni, hogy minden jól került-e a helyére, és így tovább. A kényelemért persze fizetünk, el kell dönteni, hogy mi a fontosabb. Nyugaton valószínű nem éri meg kifizetni a mérnöki munkaidőt, nálunk lehet, hogy igen.
De nekem már van S3 Transfer Acceleration-öm! - mondhatnánk. És ha tényleg van, és elégedettek vagyunk vele, akkor jó nekünk. Ha meg olyan eszközt kell beüzemelnünk, amire nem tudunk semmit hegeszteni, ami kezeli az S3 API-t, de elérjük a fájlokat NFS-en vagy SMB-n, akkor megint csak a DataSync lesz a barátunk.
De még van ám kérdésem, amire nem válaszoltál! - mondhatod. Nos, rendben, van a honlapunkon egy remekbe sikerül widget, tedd fel nyugodtan a kérdésedet:) Addig is üdv Neked.